

IntellaNOVA Dean’s List #11: The Most Powerful Data Transformation Platform for Vector Databases and Retrieval-based AI Models with Unstructured
I caught up with Brian Raymond, co-founder of Unstructured Data, at Databricks Summit. We dove into the nitty-gritty of how Unstructured Data helps enterprises simplify their workflows through innovative pre-processing services. If you’re into AI and data transformation, you’ll want to stick around.

What is Unstructured Data?
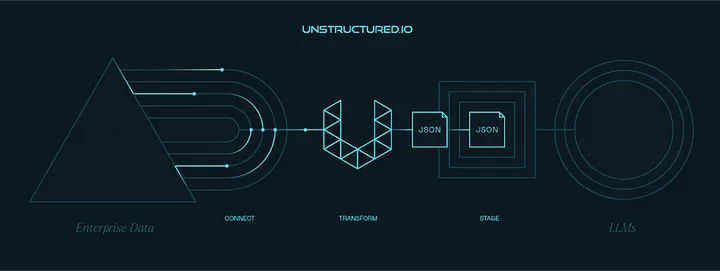
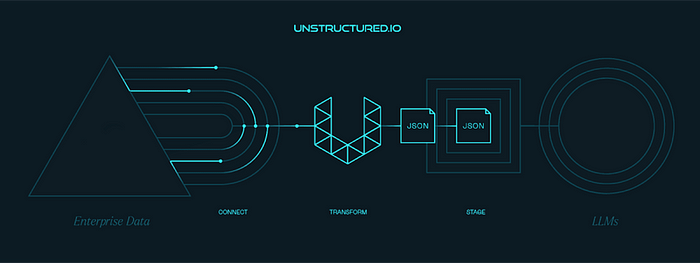
Unstructured Data is an industry leader in data ingestion and pre-processing. Their service is quite straightforward: they take in data from over 25 different file types and output clean, curated JSON. That’s right — whether you’re dealing with PDFs, PowerPoints, emails, or chat logs, it all gets processed and delivered as JSON on the other side. This streamlined approach has made Unstructured Data a go-to for many large organizations looking to manage their data more effectively.

But Is It Just an ETL Tool?
When I first heard this, my mind went straight to data integration or ETL (Extract, Transform, Load) tools. I was curious to know if Unstructured Data was just another player in this crowded space. Brian cleared it up right away.
Unstructured Data does offer a range of connectors, but the real magic lies in their focus on the “T” of ETL: transformation. Their primary goal? To transform raw data into “RAG-ready” data (Retrieval Augmented Generation). This is critical for organizations that want to leverage large language models (LLMs) and vector databases.
The RAG-Ready Process
Brian broke it down for us: in order to fully utilize your data in conjunction with vector databases and retrieval-based AI models, the data first needs to be structured. That means converting everything into JSON or Markdown, chunking it, summarizing it, and generating embeddings.
And here’s the kicker; they handle the most challenging part. That is transforming raw data into JSON. If you’re an enterprise dealing with large volumes of human-generated data like PDFs, presentations, or emails, Unstructured Data makes the pre-processing seamless, allowing you to focus on more strategic initiatives.
Real-World Use Case: Search and Chat on Your Data
One of the most common use cases for Unstructured Data is enhancing search or chat functionalities on large datasets. For example, large organizations generate mountains of human-generated data every day. Unstructured Data steps in by pulling all that content — PowerPoints, PDFs, emails, etc. — and delivers it in a format ready to be ingested into a vector database. This enables companies to interact with the data in real-time, using it for search, chat, or even QA tasks with the help of LLMs.
Why You Should Consider Unstructured Data
If your organization is looking to process data from 25+ different file types and streamline the delivery of clean, structured data to your vector database, Unstructured Data could be the answer. Their focus on simplifying the pre-processing stage allows enterprises to make the most of AI without being bogged down by data transformation challenges.
Conclusion
As AI reshapes industries, having structured, AI-ready data is critical. Unstructured Data simplifies the complex task of transforming unstructured files into JSON, enabling seamless integration with vector databases and large language models. Their solution empowers organizations to unlock insights from vast amounts of data, making advanced AI applications like search and chat more accessible. If you want to streamline your data workflows and stay ahead in AI, Unstructured Data is a valuable tool to consider.
Watch the video on youtube
https://www.youtube.com/watch?v=W5W1jsom58o