



Data Wars 2024: Dask vs. Spark, Vector Showdown, AWS re:Invent Breakthroughs, and Fivetran’s Data Revolution
The Database Face-Off: Are Vectors the Future or Just Hype?
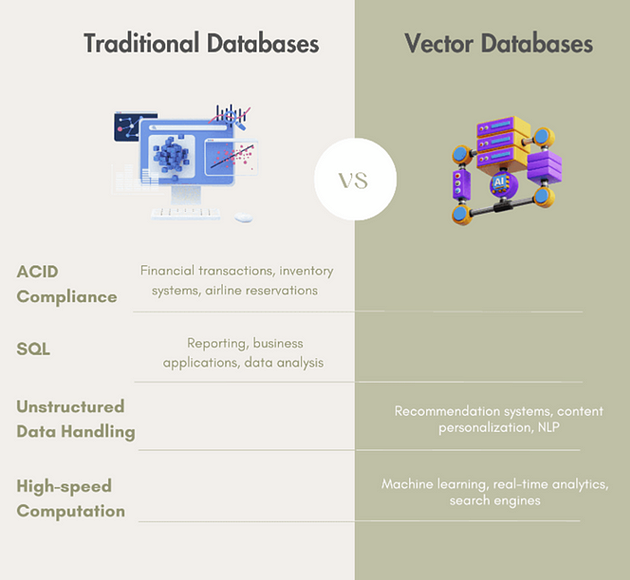
The rapid rise of vector databases has sparked debate about their role compared to traditional databases. While traditional relational databases like MySQL, Oracle, and PostgreSQL have long been essential for structured data, transaction processing, and SQL-based queries, vector databases are purpose-built for modern AI and machine learning (ML) applications. Vector databases store embeddings — mathematical representations of data points in vector spaces — enabling fast similarity searches crucial for AI-driven recommendations, semantic search, and real-time personalization. Unlike traditional databases that prioritize structured, ACID-compliant data, vector databases handle unstructured, high-dimensional data at scale. Players like Pinecone, Milvus, and LanceDB have emerged to address these new demands. However, the industry is moving towards hybrid systems, blending vector capabilities into relational databases like PostgreSQL and SingleStore. The future of data management isn’t a binary choice but a convergence, with AI and ML innovations driving the demand for more specialized, hybrid data systems.
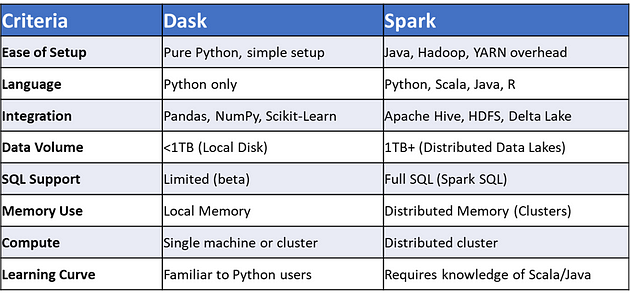
Dask vs. Spark: Which Big Data Tool Should Data Scientists Choose?
Dask and Spark are both essential tools for handling big data, but each serves distinct purposes. Dask, a pure Python library, scales familiar libraries like Pandas and NumPy, allowing for parallel execution and seamless integration with Scikit-Learn, making it ideal for data scientists who prefer a Python-native environment. It excels in simplicity, ease of setup, and handling datasets smaller than 1TB on local storage. In contrast, Spark, originally built for Hadoop, is designed for enterprise-scale workloads, efficiently processing terabytes to petabytes of data across distributed clusters. Its SQL-like querying capabilities, integration with the Apache ecosystem, and ability to handle large datasets on HDFS or cloud storage make it the go-to choice for large-scale, enterprise-level projects. Ultimately, Dask is best for Python-first workflows and smaller datasets, while Spark shines in handling massive, distributed datasets with SQL and enterprise data lakes.
Re-Cap — AWS re:Invent 2024: Game-Changing Announcements in AI, Databases, and Cloud Innovation
AWS re:Invent 2024 unveiled game-changing innovations across AI, databases, and cloud technology, empowering data engineers, analysts, and business users. Key highlights included AWS Clean Rooms for multi-cloud collaboration, Amazon Connect’s AI-driven customer engagement tools, and Amazon MemoryDB’s multi-region low-latency access. Groundbreaking advancements like Amazon Bedrock’s RAG-focused LLM tools, CloudWatch Database Insights’s observability enhancements, and OpenSearch Service’s integration with Security Lake addressed critical pain points. Day 2 introduced Aurora dSQL for distributed databases, Tranium 2 chips for generative AI training, and the cost-saving Amazon Nova foundation model. Day 3 showcased Bedrock’s expanded AI marketplace, Prompt Caching for efficiency, and Kendra’s AI-powered search. AWS also emphasized security with new GuardDuty capabilities and competencies for AI security and forensics. Together, these innovations underscore AWS’s continued dominance in cloud solutions, fostering scalability, efficiency, and enhanced security for global enterprises.

Unleash the Power of Data Movement with Fivetran!
Fivetran revolutionizes data movement with 500+ connectors and 17+ destination options, enabling seamless data transfer across lakes, warehouses, and vector databases. It offers speed, scalability, and flexibility, allowing companies like HubSpot to power AI models with real-time, AI-ready data. With features like the “Buy Request” program for new connectors and support for diverse data destinations, Fivetran ensures timely insights and future-proofs modern data infrastructure. By simplifying access to critical data, Fivetran becomes an essential tool for AI development, data-driven decision-making, and scalable, modern data operations.
